Aprenda Big Data e Computação Distribuída
Pule de pequenos datasets locais para manipulações massivas de dados em cluster. Do zero absoluto ao Machine Learning e pipelines complexos com o framework de dados mais cobiçado por grandes empresas.
CONHECIMENTO QUE PAGA DE R$ 8.000 A R$ 20.000 REAIS POR MÊS

Big Data na Veia
Arquiteturas com RDDs e DataFrames distribuídos onde a lentidão do Python single-thread morre.
Performance Extrema
Avaliação preguiçosa (Lazy Evaluation). Seus dados só processam o estritamente necessário na hora exata.
Mercado Premium
Vagas exigindo Spark/Databricks possuem algumas das maiores médias salariais de tecnologia no Brasil.
Acesso Vitalício
Estude no seu tempo. Módulos atualizados periodicamente não serão cobrados de você futuramente.
Você bateu no teto?
Scripts em Python e planilhas demorando horas? Não é sua culpa. É a ferramenta.
Processamento vertical (adicionar mais RAM num único PC) tem limites físicos. A única saída corporativa do mercado para escalar infinitamente se chama Processamento Paralelo.
Teto de Memória
Sua máquina (ou do servidor) trava com 'MemoryError' sempre que tenta abrir um CSV grande no Pandas.
Lentidão Radical
Trabalhos de processamento que levam 10 horas em Python puro atrasando as análises dárias.
Barragem Salarial
Sente estagnação porque vagas que pagam mais de R$ 10k exigem 'conhecimento em computação distribuída / Spark'.
Modelos Devagar
Possui modelos de Machine Learning excelentes que morrem de lentidão ao tentar colocar em produção.
Documentação Torta
Perdeu a paciência com documentação pesada e incompreensível sobre configuração de clusters e nós.
Perda de Precisão
Acaba fazendo amostragem dos dados (pegando só uns 10%) porque sua ferramenta atual não aguenta o dataset inteiro.
Data Science em Escala
É pra você o PySpark na Prática?
Se você já tem intimidade mínima com análise de dados básica ou noções de programação, poderá expandir seus limites aqui de Terabytes para Petabytes de dados.
Analistas travados no Excel/Pandas
Mude de nível. Pare de travar planilhas com arquivos de 2 milhões de linhas. Com o PySpark você manipulará Terabytes sem suar a camisa da sua máquina.
Engenheiros de Dados Aspirantes
O Spark é a espinha dorsal de qualquer arquitetura moderna de Data Lake (Medallion architecture). Aprenda a criar pipelines distribuídos verdadeiros.
Cientistas de Dados (AI / ML)
Destrave todo o potencial preditivo treinando algoritmos de Machine Learning diretamente nos nós de um cluster gigantesco e de forma parelelizada usando a biblioteca MLlib.
01Introdução
Diretrizes gerais do curso
Instalação local do PySpark e Java
Configuração de ambientes Cloud (Databricks / AWS)
02Conhecendo o PySpark
A arquitetura do Apache Spark e RDDs
Primeiras consultas usando DataFrames
Filtros e criação de colunas condicionais (when/otherwise)
03Manipulação de Dados Essencial
Agrupamentos e sumarização (groupBy/agg)
Ordenação dinâmica e cruzamentos complexos (JOINs)
União, empilhamento e lida com dados ausentes/duplicados
04Técnicas Avançadas de Tratamento
Pivot e Unpivot escalar em DataFrames
Uso da interface SQL nativa do Spark
Integração híbrida entre Pandas e Spark
05Análise Avançada de Dados
Funções Janela (Window Functions) para cálculos em lote
Cálculos não lineares e acumulativos globais
Criação de UDFs (User Defined Functions) personalizadas
06Data Visualization em Larga Escala
Transformação de big data para visualização sintética
Gráficos de dispersão, barras e histogramas
Integração segura com bibliotecas de plotagem
07Algoritmos de Machine Learning
API MLlib do Spark para modelagem distribuída
Random Forest e Support Vector Machines (SVM)
K-NN, Redes Neurais e Pipelines de Machine Learning
08Desafio Final (Projeto do Mundo Real)
Case end-to-end de negócio real
ETL completo desde o dado bruto até o pipeline final
Avaliação definitiva das suas habilidades em Big Data
P1Prova Nível Básico (Teórica)
Otimização da execução e conceitos base do Spark no backend
Questões de múltiplas escolhas sobre transformações e ações
P2Prova Nível Avançado (Prática)
Construção de um ETL com regras de negócios restritas
Modelagem real de base de Big Data
Como essa habilidade afeta carreiras e salários reais
Veja o que os membros dizem sobre o método de ensino.

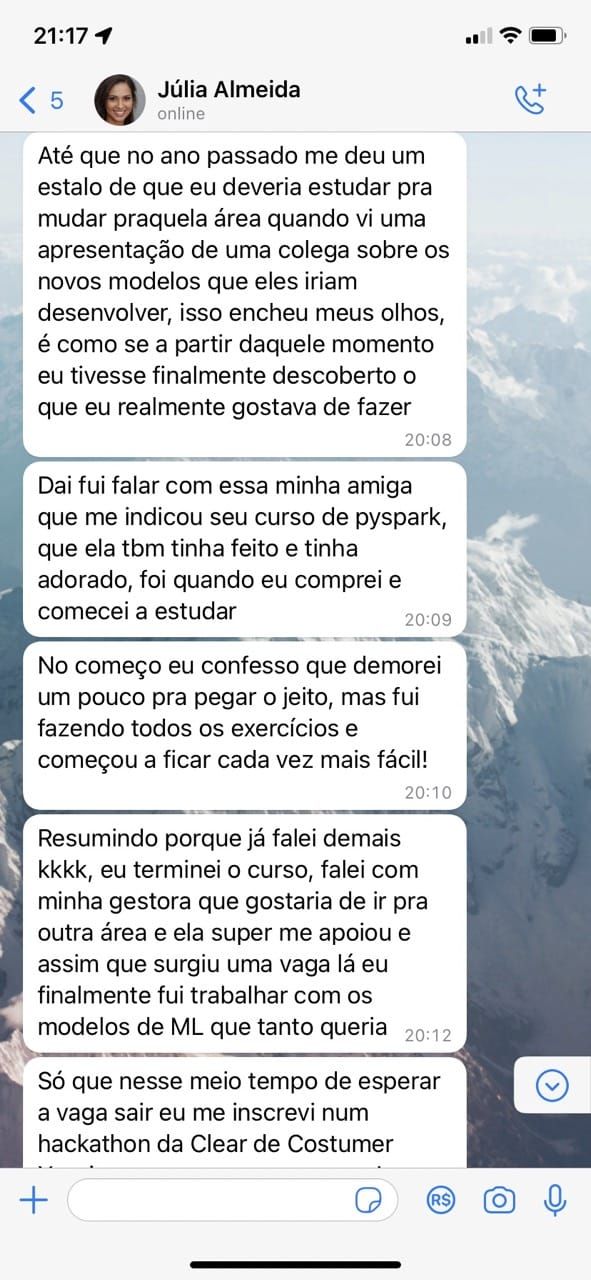
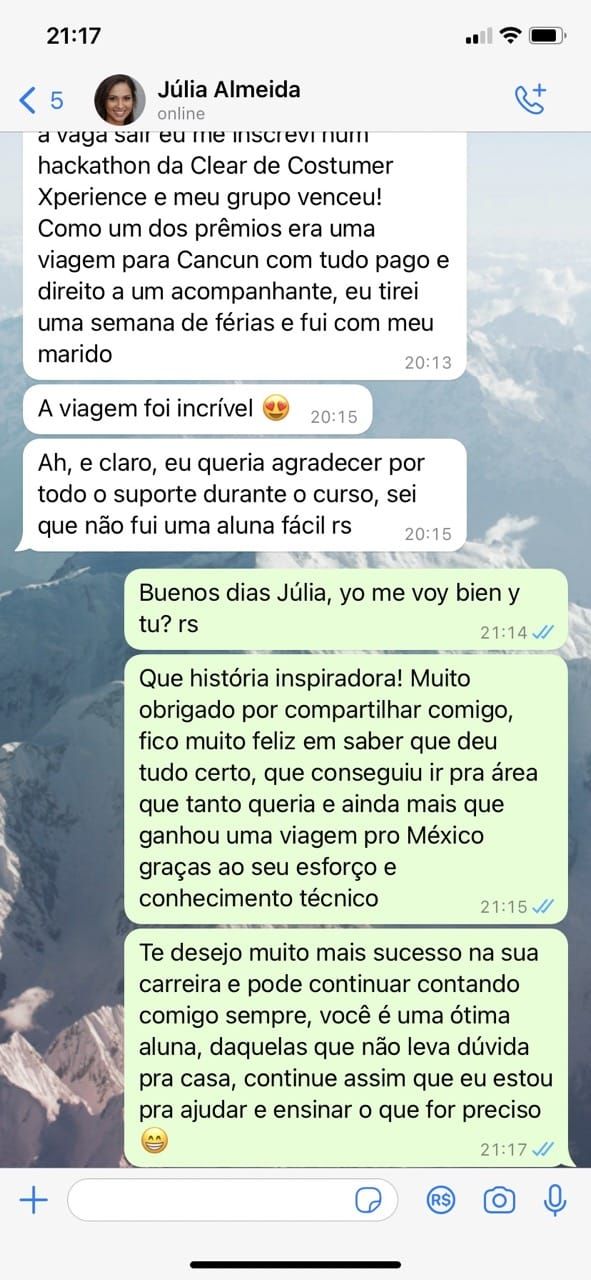

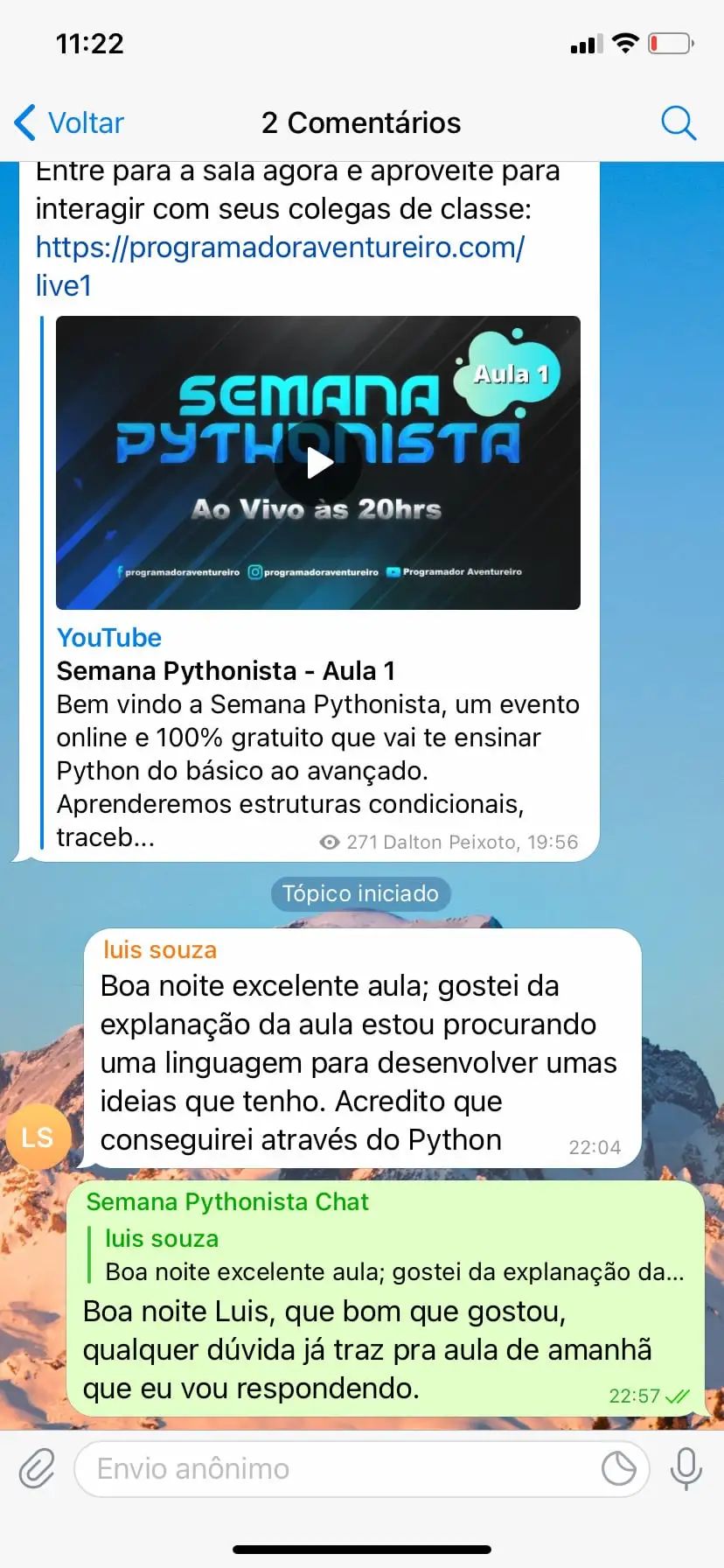
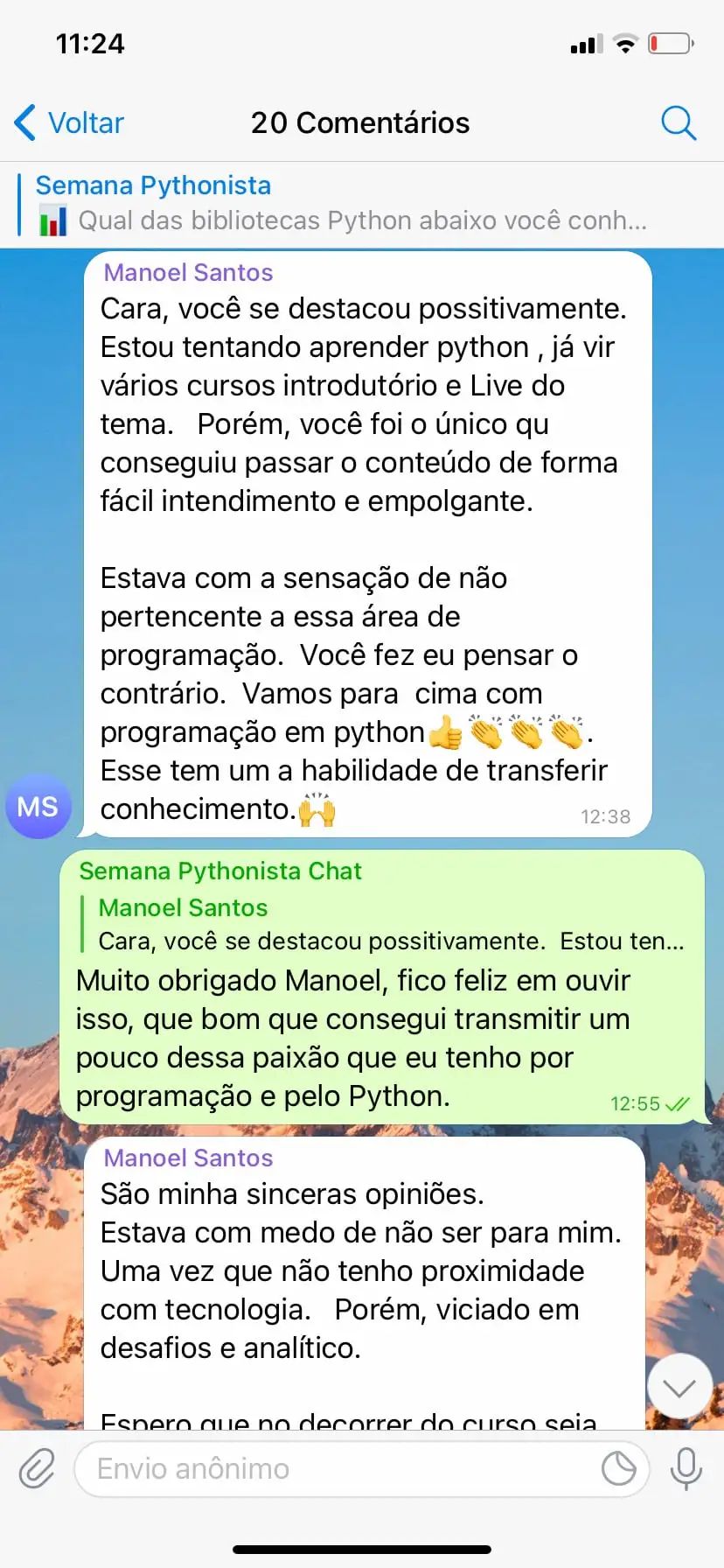
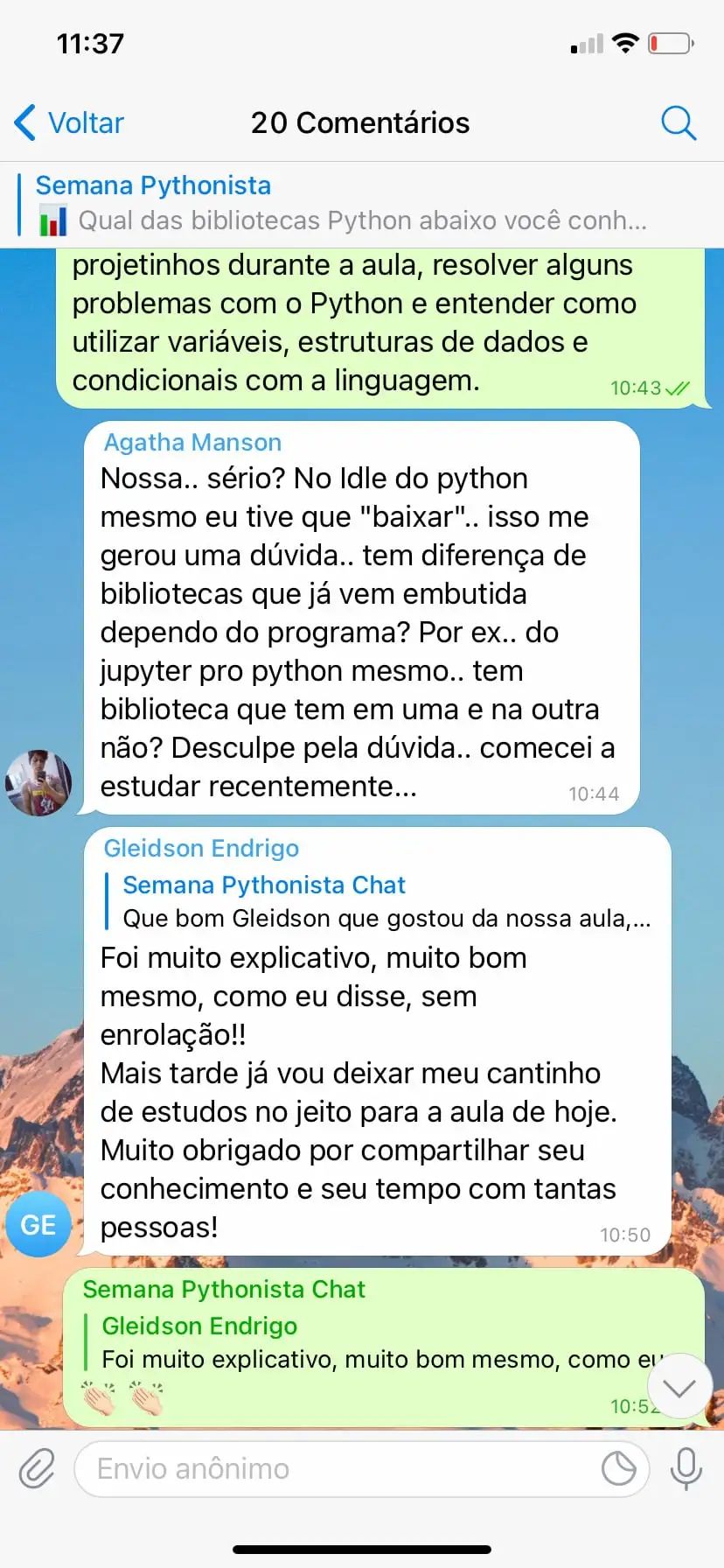
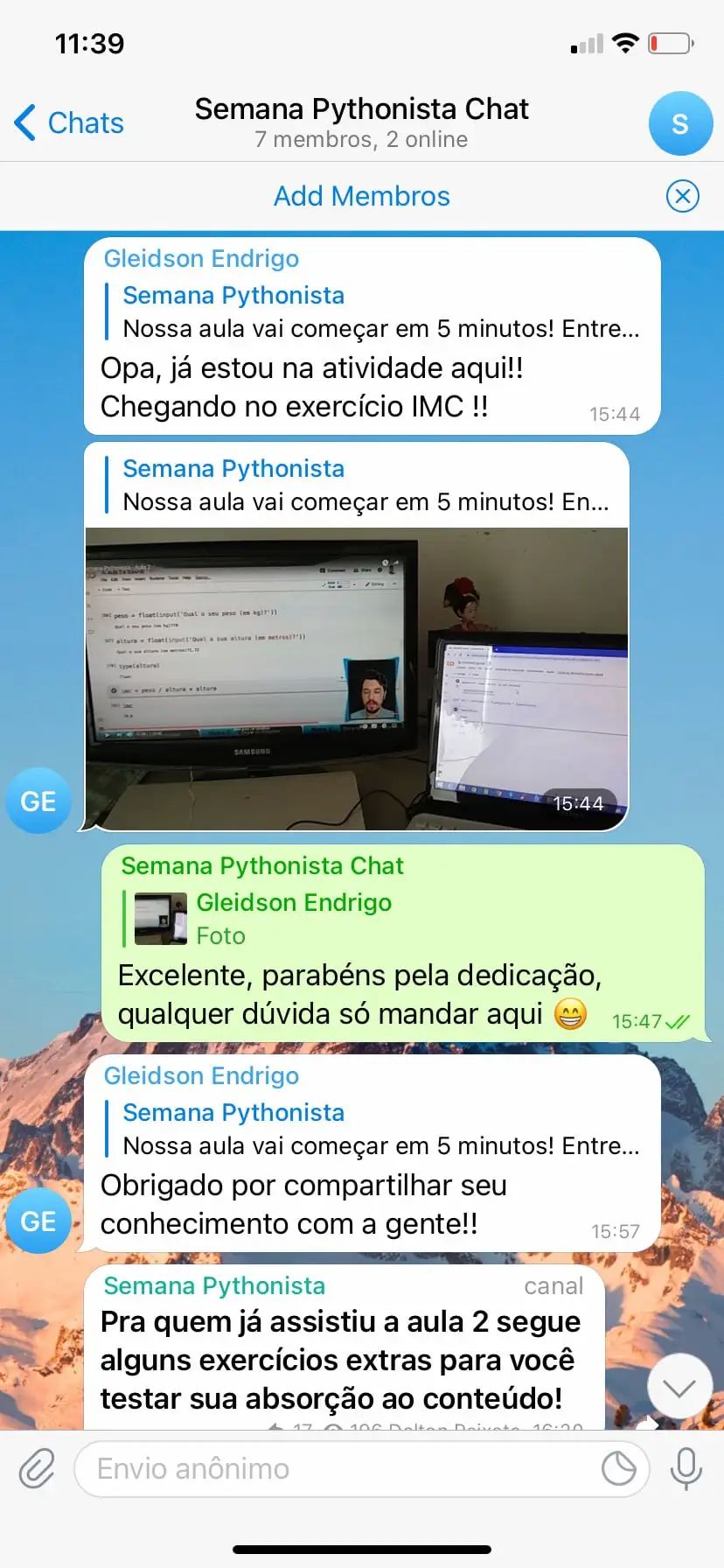
Aulas Teóricas e Práticas
Provas (Teórica e Prática)
Alunos matriculados nessa formação

Dalton Peixoto
TECH LEAD & DATA SCIENTIST
CONHEÇA SEU
INSTRUTOR
Dalton Peixoto é profissional com mais de 13 anos de experiência no mercado de desenvolvimento e tecnologia, formado em desenvolvimento de sistemas e especializado em ciência de dados.
Trabalhou diretamente no desenvolvimento de mais de 182 aplicativos e sistemas, desde projetos governamentais para países como Chile, Argentina, Brasil, Canadá e Austrália. Como cientista de dados desenvolveu 12 modelos de Machine Learning para análise de crédito veicular e propensão de risco em empresas como Banco Santander, Serasa e Banco Itaú.
"Nos últimos 6 anos ajudei milhares de alunos a entrarem para a área de tecnologia e mais que dobrar seus salários, e você é o próximo!"
Evolua de análises locais
para Big Data Corporativo.
O treinamento completo de Apache Spark rodando em Python. O skill ausente na vasta maioria de candidatos à Engenharia de Dados.
A formação definitiva de extração, limpeza (ETL) e análise sobre conjuntos massivos de dados.
- +70 Aulas do absolut zero ao avançado
- 2 Provas reais para testar a absorção
- UDFs, Window Functions, e Manipulação Avançada
- Deploy de Algoritmos (Machine Learning Distribuído)
- Acesso Vitalício sem cobranças extras
- Suporte especializado para dúvidas diárias
- Acesso a outros cursos da plataforma
Pagamento único. Acesso vitalício.
ou R$ 197 à vista
Garantia incondicional de 7 dias
Assinatura anual ALL-ACCESS: todos os cursos, bônus e lançamentos em um único plano.
💰 Você economiza mais de R$ 3.500 versus comprar tudo separado
- Acesso integral por 1 ano ao PySpark na Prática
- Acesso a TODOS os 37+ cursos
- Acesso a SQL, Especialista Python, Automação
- Apostilas Digitais e Livas exclusivas
- Certificados para cada formação concluída
- Suporte prioritário à Comunidade PRO
Assinatura anual • Renovação opcional
ou R$ 597 à vista
= R$ 1,64/dia por acesso a TUDO
Risco zero. Garantia de 7 dias sem perguntas.
O Mercado
Garantia incondicional
Em Escala Real
SATISFAÇÃO INCONDICIONAL GARANTIDA
Eu assumo todo
O seu risco
Entre, acesse todo o material, conheça os projetos por dentro e decida com calma.
Se durante o período de 7 dias você não sentir que esse é o melhor treinamento para a sua carreira, eu devolvo todo o seu dinheiro imediatamente, centavo por centavo e sem letras miúdas.
Basta enviar um único e-mail para [email protected] ou solicitar o estorno diretamente dentro da plataforma. Seu reembolso será processado na hora.
AINDA TEM DÚVIDAS?
Se você está em dúvida, nosso time de suporte via WhatsApp está à disposição para esclarecer tudo e ajudar na sua decisão.
CHAMAR NO WHATSAPPPerguntas Frequentes
Confira as respostas das dúvidas mais frequentes ou nos chame no suporte.
Preciso de um computador muito potente para aprender PySpark?
Não necessariamente. Você pode rodar pequenos clusters localmente para aprender a lógica, ou, melhor ainda, utilizar ambientes gratuitos na nuvem (como Databricks Community) ensinados no curso, onde a exigência do seu hardware é zero.
Já preciso saber muito de Python para fazer o curso?
Recomendamos que você conheça a lógica básica do Python (variáveis, loops, funções). Se você já usou a biblioteca Pandas, a transição para os DataFrames do PySpark será muito fluida.
O curso cobre Databricks?
Sim! Um dos módulos introdutórios cobre como você pode rodar e orquestrar seus scripts de PySpark usando o Databricks, que é o padrão de mercado para muitos Data Lakes modernos.
Vou conseguir certificado?
Sim, ao completar todas as aulas e os projetos de fixação, você emitirá seu certificado aceito pelo mercado profissional como horas de atualização técnica.
Acesso vitalício, mesmo?
Simples e direto: uma vez inscrito, você não perde mais o acesso. Nem ao conteúdo atual, nem a futuras gravações de PySpark que entrarem no módulo.